Intro to ColBERT
Do you have a query? Do you have documents that might answer it? Let's focus on the question of our times: given a query, how can we fetch the most relevant documents?
Vanilla RAG
Usually, a dense retrieval RAG pipeline goes like:
- Embed your query
- Go to your store of document vectors & find the top-k documents whose embeddings are closest to your query (ie. most semantically similar)
- Feed these k documents to your LLM as context
Note: Different RAG pipelines are variations on each of these steps.
All is well, right? Not quite. Document vectors make tradeoffs between capturing global & local context:
- If your documents are small, the doc vector won't capture overall context
- If they're too large, the vectors will miss the intricate details of the document
Take this example: a dense embedding will encode 'I love to run' & 'I hate to run' pretty close to each other.
ColBERT
ColBERT solves this; it introduces the following powerful ideas:
- Instead of matching a single query vector against a single document vector (and missing lots of context, as mentioned above), it encodes an embedding vector for each token of the query and document and makes pairwise comparisons. This embedding is encoded via BERT (so of course, it makes use of the power of transformers in keeping context from other tokens). Each of these multi-vector sets are referred to as a 'bag of embeddings'.
The query-doc similarity score is computed as follows:
- For each token vector in the query, finds the closest document token and computes the cosine similarity (referred to as the max-sim score)
- Adds the max-sim scores across all query tokens to get the final similarity score between the query and that document
- Since this computation is essentially doing nearest neighbour search, a well-studied problem, ColBERT prunes out a lot of low-scoring candidate docs pretty quickly & makes ColBERT quite scalable
In the end, you get embeddings that capture both keyword information as well as some context at the level of a few tokens. You can then ask a query in the style of the responses you want.
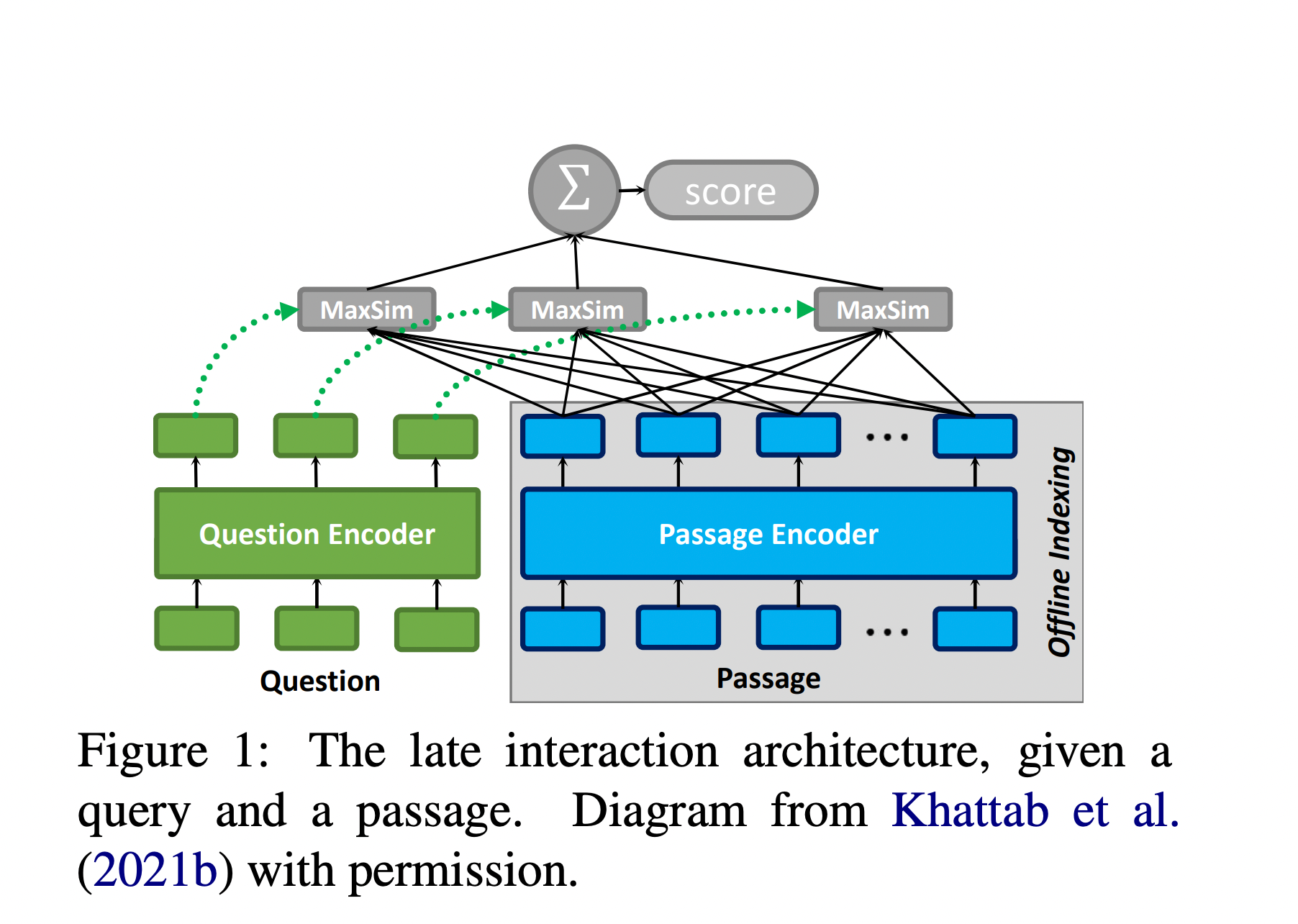
Figure 1: The late interaction architecture. Diagram from Khattab et al. (2021b).
ColBERT v2 Improvements
Since the ColBERT paper in 2020, ColBERT v2 has come out. The key improvement is the efficient encoding of vectors, which falls from the following observation:
- Most token vectors tend to organize around a few thousand clusters
- Thus each vector can be represented as the closest centroid plus a small delta that nudges the dimensions in the right direction. This results in an encoding of around 20 bytes (which is incredibly small)
- So while ColBERT v1 was ~10x the size of a comparable RAG vector store of the same data, ColBERT v2 is comparable in size (or just slightly larger)
When a document is embedded by ColBERT, it isn't represented as a document, but as the sum of its parts. This fundamentally changes the nature of training our model, to a much easier task: it doesn't need to cram every possible meaning into a single vector, it just needs to capture the meaning of a few tokens at a time.
Example: Learning about the Industrial Revolution
Let's use the Wikipedia page on the Industrial Revolution as our corpus. When we ask ColBERT: "how did the economy change after the industrial revolution?", we get highly relevant passages about GDP growth, standard of living improvements, and economic transformation.
More Complex Query
Let's make the query more complicated: "From where did British iron manufacturers use considerable amounts of iron?"
ColBERT returns the text "Up to that time, British iron manufacturers had used considerable amounts of iron imported from Sweden and Russia to supplement domestic supplies" in the highest-ranked result, while dense embedding retrieval did not rank it even in the top 5. ColBERT can do both semantic as well as keyword matching!
Parting Thoughts
I'm not asking you to trust me blindly here; this is a tiny corpus & does not reflect the tradeoffs you'll make in a production system with cost, latency, size & snippet quality.
Having good benchmarks for your use case will help you better understand what the best system is but I think you should at least give ColBERT a serious look!